Description
Beam search is a search algorithm to find the best choice from many options. It explores a graph by expanding the most promising node in a limited set. A beam search is usually used in situations where there isn’t a way to store the entire search tree in memory.
where is it used in DL?
sequence to sequence models like neural machine translation
how is it used in DL?
used to find the next best word, can be EOS
For example:
In NMT there are lots of possible combinations of words for a translation but we want to pick the best one, aka the one with the max probability distribution, and not one at random.
Interesting things to note:
When beam width = 1, then beam search is essentially a greedy algorithm
Beam search multiplies the log of the probabilities of the words to find the max probability - this leads to beam search favoring very short translations. This is kind of fixed by dividing it by the number of tokens.
Code
def beam_search_decoder(encoded_data, beam_width: int):
sequences = [[list(), 1.0]]
# walk over each step in sequence
for row in encoded_data:
all_candidates = list()
# expand each current candidate
for i in range(len(sequences)):
seq, score = sequences[i]
for j in range(len(row)):
# why are we taking the log of the product of the probabilities
# instead of just the product of the probabilities?
# the probabilities are all numbers less than 1,
# multiplying a lot of numbers less than 1 will result in a very smol number
candidate = [seq + [j], score * -np.log(row[j])]
all_candidates.append(candidate)
# order all candidates by score
ordered = sorted(all_candidates, key=lambda tup: tup[1])
# select beam_width best
sequence = ordered[:beam_width]
return sequence
Math
How the algorithm works from Andrew Ng’s coursera course:

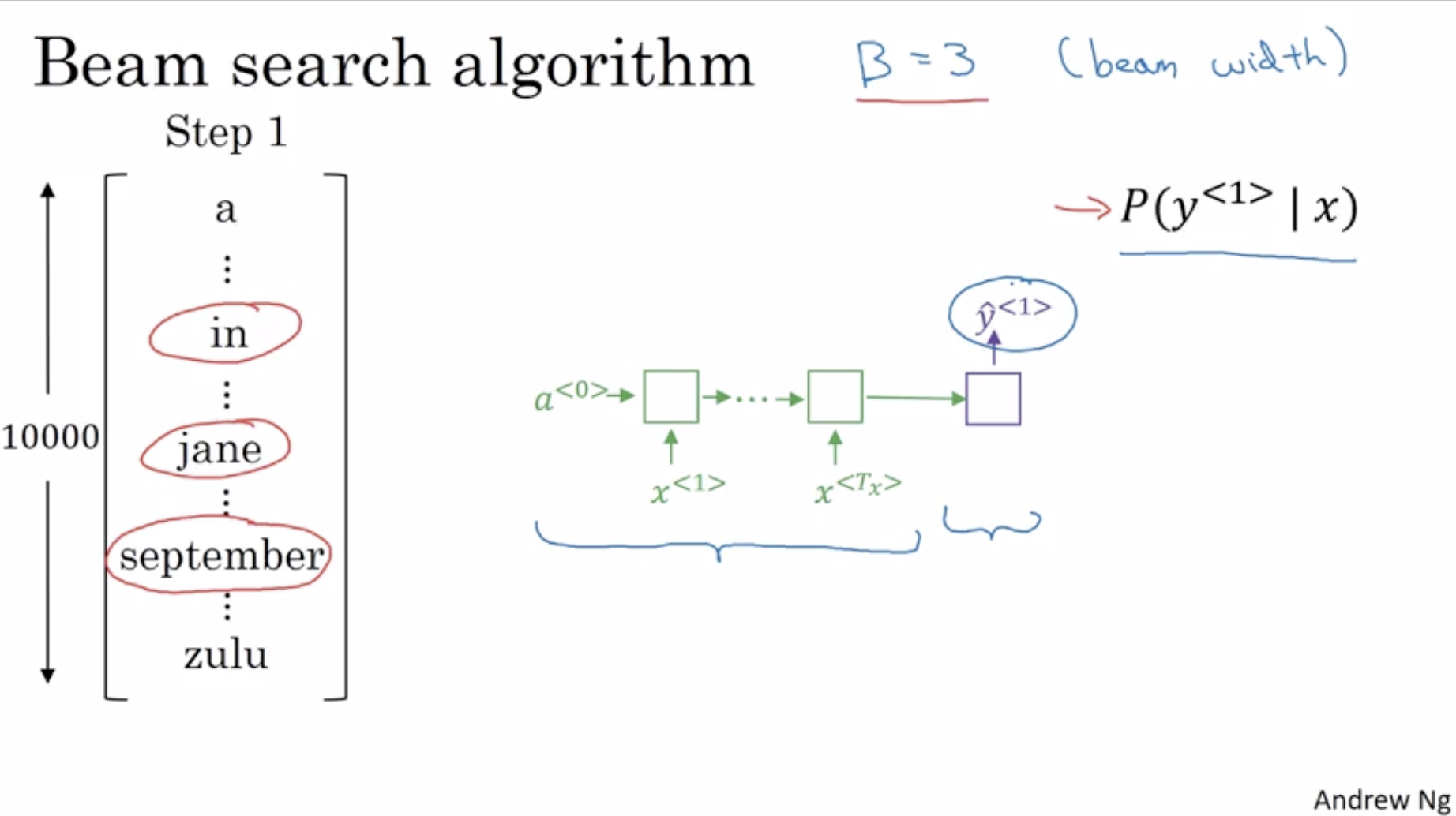
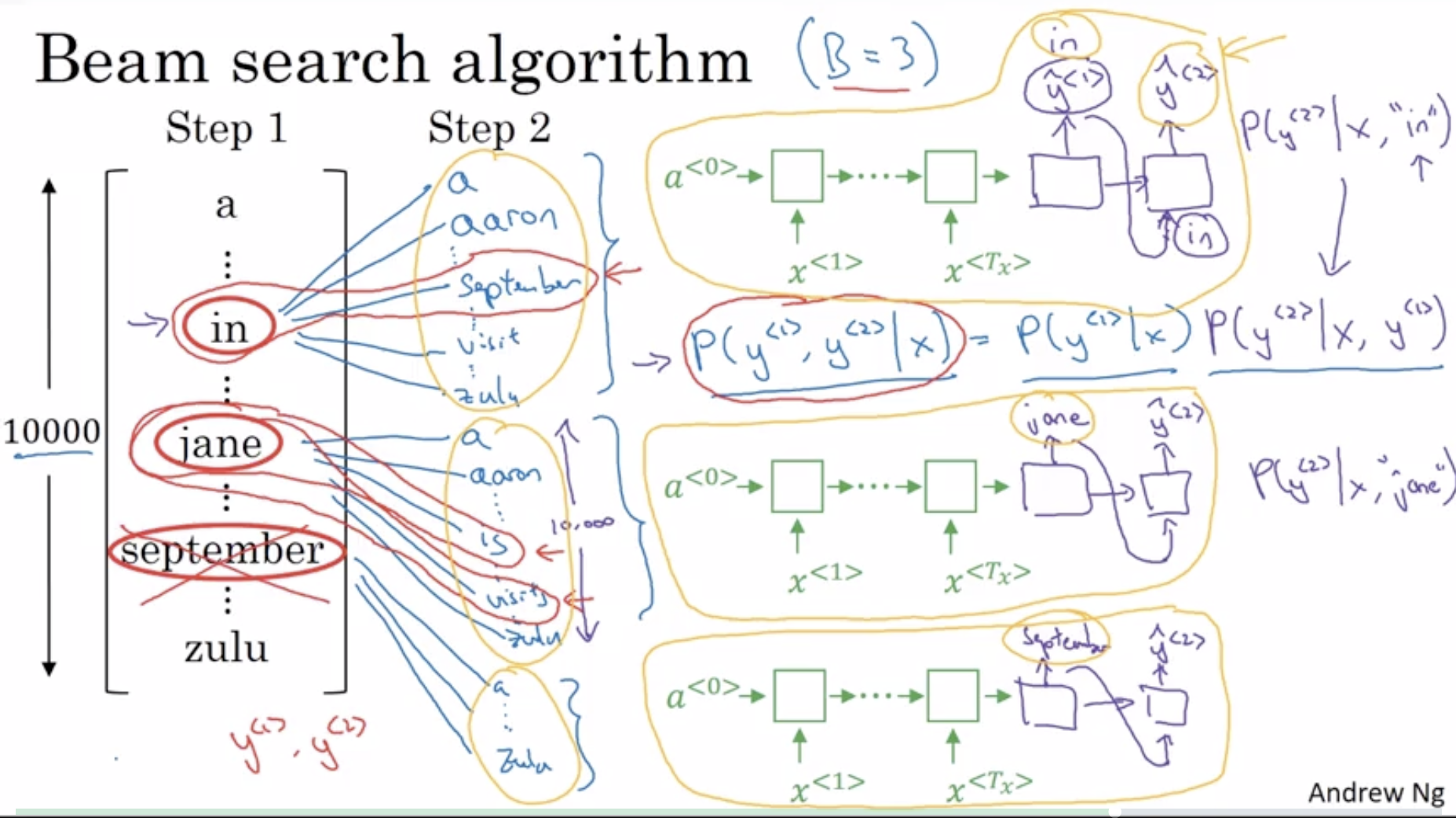
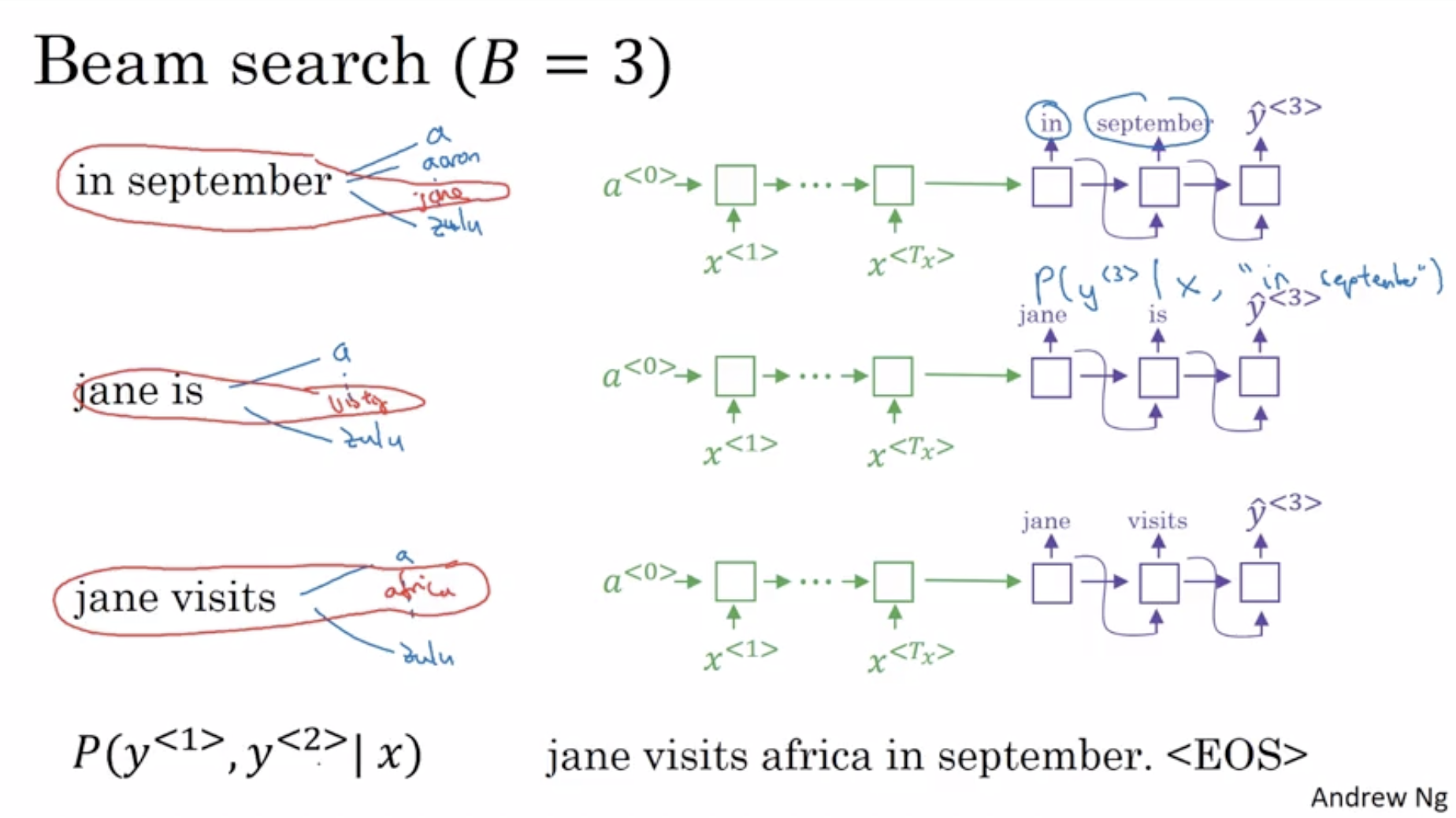
History
The term “beam search” was coined by Raj Reddy, Carnegie Mellon University, 1977.