What is it
Grounded Language Learning is the process of learning representations for words based on non-linguistic experience.
Grounded language learning works to make use of language, multimodal information, and interactive environments. This research works toward achieving natural language understanding. Currently, natural language understanding is commonly tested by language models from text-only corpora. This approach with language models is based on the idea that the meaning of a word is based on only its relationship to other words. This is also called a distributional notion of semantics. SOTA language models are incredible for many different tasks and even come close to beating humans at natural language understanding benchmarks. However, there are critiques around NLU benchmarks, and grounded language learning argues that the words are not grounded in anything and, therefore, actually meaningless. With grounded language learning, the hope is to be able to create models that can understand and generalize well to their context.
From VIGIL: Visually Grounded Interaction and Language
“In neuroscience, recent progress in fMRI technology has enabled better understanding of the interaction between language, vision and other modalities suggesting that the brains share neural representations of concepts across vision and language. In concurrent work, developmental cognitive scientists have argued that word acquisition in children is closely linked to them learning the underlying physical concepts in the real world and that they generalize surprisingly well at this from sparse evidence.”
Tasks
Visual QA

Embodied QA
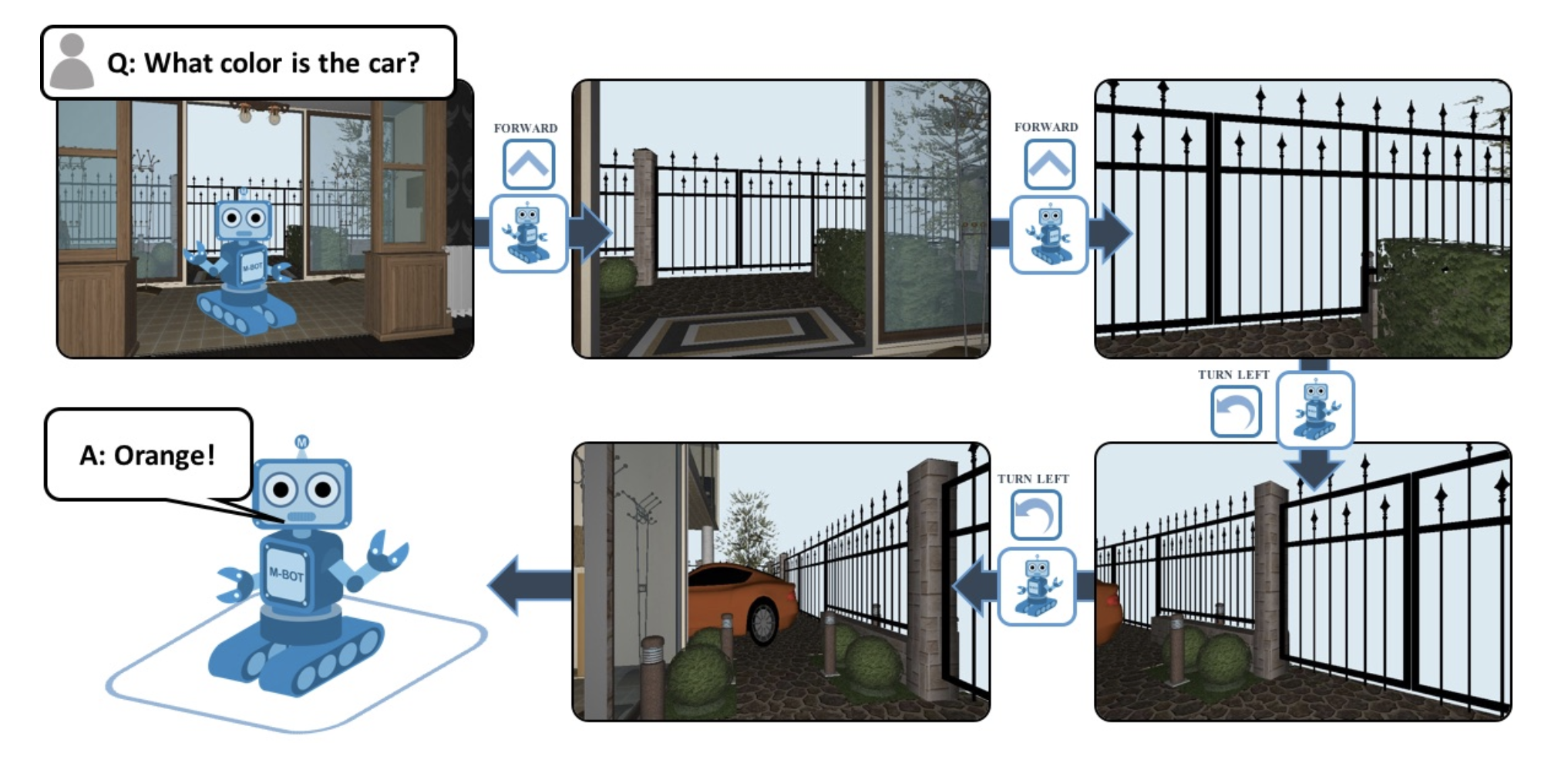
Captioning
Visual-Audio Correspondence
Look, Listen, Learn “what can be learned by training visual and audio networks simultaneously to predict whether visual information (a video frame) corresponds or not to audio information (a sound snippet)?”
Embodied Agents Performing Interactive Tasks
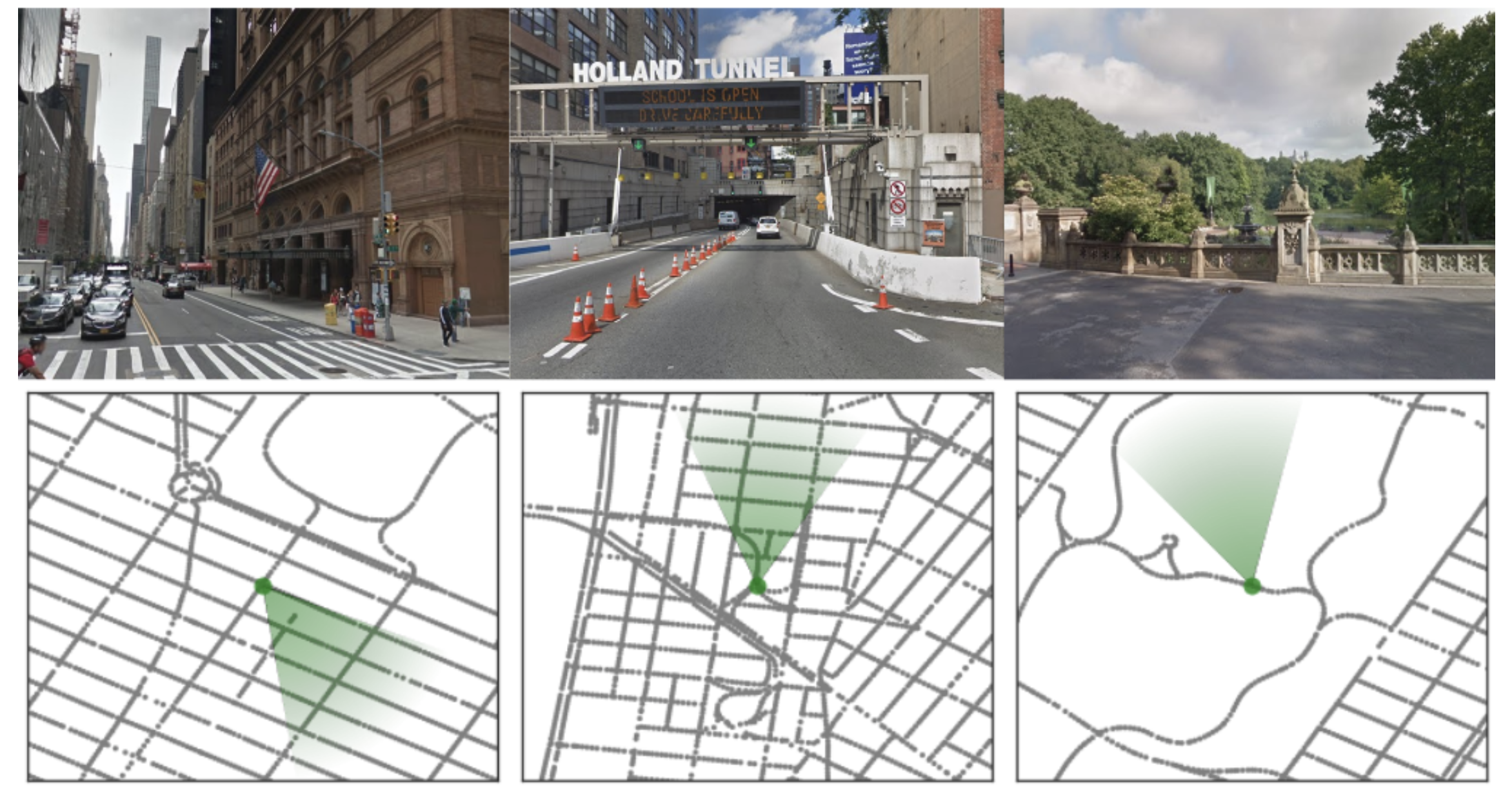
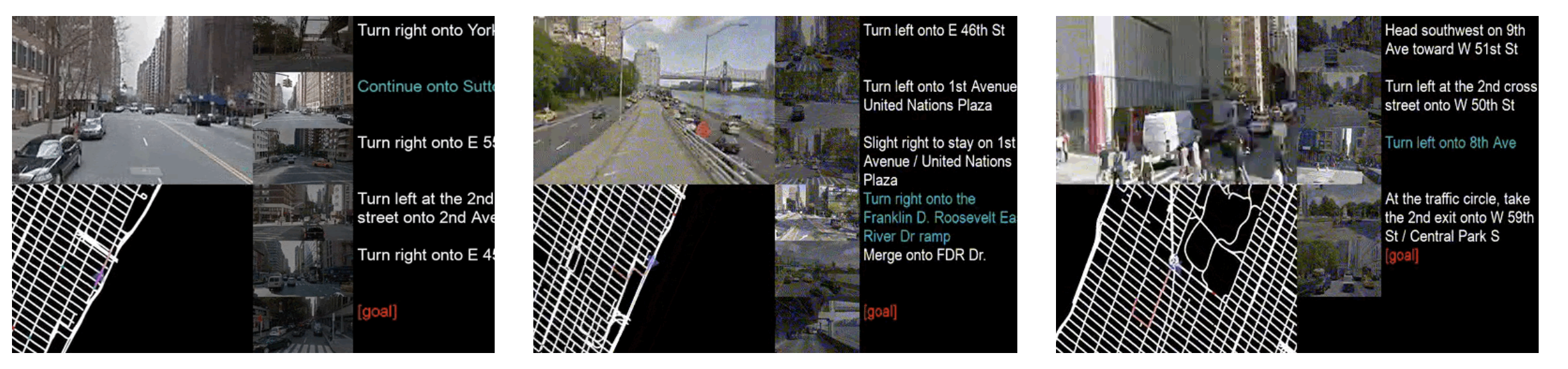
Other Games
Mechanical Turker Descent (MTD) that trains agents to execute natural language commands grounded in a fantasy text adventure game