Ahead of next week’s ICLR 2020 virtual conference, I went through the 687 accepted papers (out of 2594 submitted - up 63% since 2019!) and identified 9 papers with the potential to advance the use of deep learning NLP models in everyday use cases.
Here’s what the papers found and why they matter:
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning
Main Contribution: A commonly used task for pre-training language models is to mask the input and have the model predict what is masked. This paper introduces a new pre-training task called token detection. In the new task, the authors replace some tokens with alternatives by sampling from a generator. They then trained a discriminator to predict whether the generator replaced each token in an input or not.
Why It Matters: This task is more data efficient, learning potentially from all tokens in a dataset versus the ~15% masked in the usual approach. It shows there’s still room for additional creativity in how to train a language model.
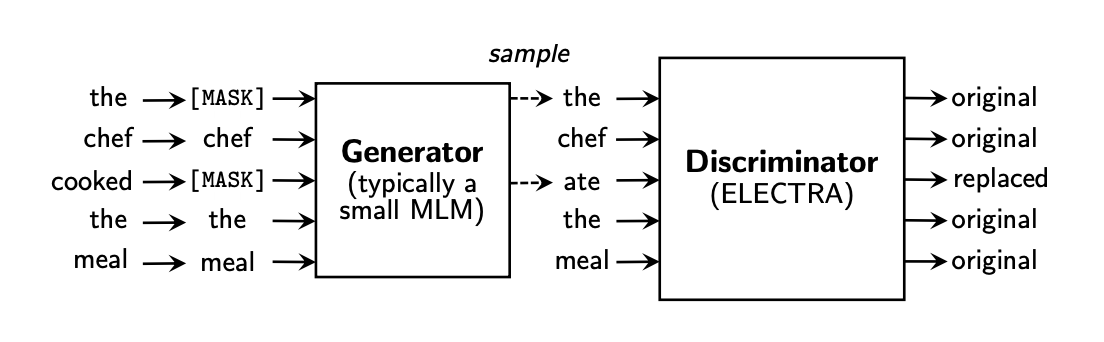 An overview of replaced token detection
An overview of replaced token detection
The Curious Case of Neural Text Degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, Yejin Choi
Main Contribution: The authors propose a new decoding strategy called nucleus sampling — which truncates the tail of the probability distribution, sampling from the dynamic nucleus of tokens containing the vast majority of the probability mass. The counter-intuitive empirical observation is that even though the use of likelihood as a training objective leads to high-quality models for a broad range of language understanding tasks, using likelihood as a decoding objective leads to text that is bland and strangely repetitive.
Why It Matters: Text degeneration is an issue even in the latest cutting edge language models. Decoding strategies are important to create more human-like text generation for various tasks. Moving away from greedy algorithms like beam search will help performance on downstream tasks.
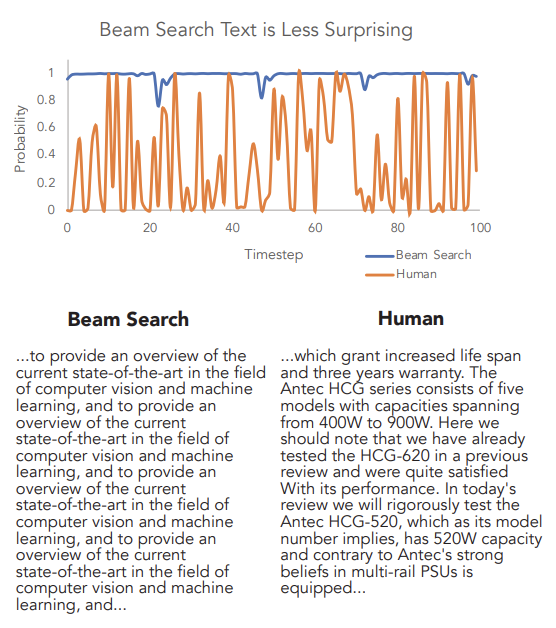 Example of beam search based generation vs human generation
Example of beam search based generation vs human generation
What Can Neural Networks Reason About?
Keyulu Xu, Jingling Li, Mozhi Zhang, Simon S. Du, Ken-ichi Kawarabayashi, Stefanie Jegelka
Main contribution: This paper introduces a framework called algorithmic alignment to measure how well neural networks perform on reasoning tasks. Neural networks that “align” with known algorithmic solutions are better able to learn the solutions. The framework roughly states that for the model to be able to learn and successfully generalize on a reasoning task, it needs to be able to easily learn (to approximate) steps of the reasoning tasks. The authors showed graph neural networks are well suited for and therefore can learn to solve dynamic programming problems.
Why It Matters: This is a dense theoretical paper explaining architectural choices people have been intuitively making and lays the groundwork for future research exploring new architectures to better fit tasks. It creates a new framework to evaluate future algorithms and tasks.
Sequential Latent Knowledge Selection for Knowledge-Grounded Dialogue
Byeongchang Kim, Jaewoo Ahn, Gunhee Kim
Main Contribution: This paper proposes a novel approach to selecting knowledge for open-domain dialogue called Sequential Latent Model which represents knowledge history as some latent representation. They do this because keeping track of knowledge history reduces the ambiguity caused from the diversity in knowledge selection of conversation but can also help better use the response information/utterances.
Why It Matters: This work shows that improving knowledge selection can make a big difference in response generation quality. This has implications for building more robust dialogue applications.
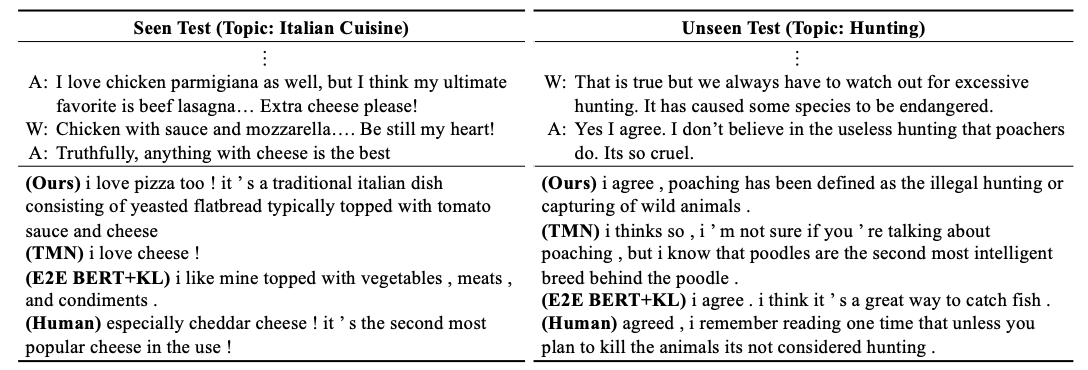 Examples of generated responses by the author’s model and baselines on Wizard of Wikipedia. TMN stands for E2E Transformer MemNet, and A and W for apprentice and wizard.
Examples of generated responses by the author’s model and baselines on Wizard of Wikipedia. TMN stands for E2E Transformer MemNet, and A and W for apprentice and wizard.
A Probabilistic Formulation of Unsupervised Text Style Transfer
Junxian He, Xinyi Wang, Graham Neubig, Taylor Berg-Kirkpatrick
Main Contribution: The authors propose a probabilistic approach to unsupervised text style transfer. This approach works by using non-parallel data from two domains as a partially observed parallel corpus. The authors’ proposed model learns to transform sequences from one domain to another domain. By generating a parallel latent sequence that generates each observed sequence, this allows the model to learn this in an unsupervised way.
Why It Matters: The paper had good results for the following tasks: unsupervised sentiment transfer, formality transfer, word decipherment, author imitation, and machine translation. Some of these could be useful features for future writing applications. The approach introduced in the paper does not require paired training data, which makes data collection for style transfer easier.
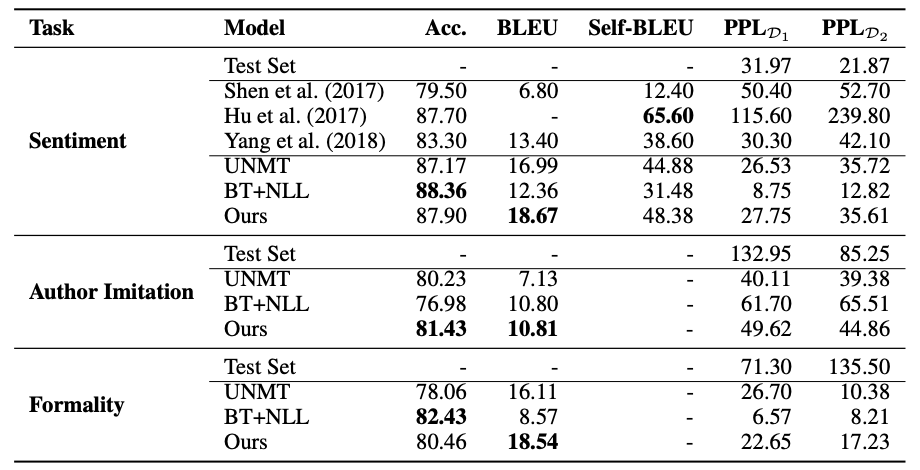 Results on the sentiment transfer, author imitation, and formality transfer
Results on the sentiment transfer, author imitation, and formality transfer
ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut
Main Contribution: ALBERT is an extension of BERT that tries to answer the question: are larger models the answer to NLP tasks? Albert achieves SOTA results by cross-layer parameter sharing. By sharing parameters, ALBERT can be smaller with similar performance. The best results from ALBERT are with more parameters — but it still trains faster than BERT. And when they train for the same amount of wall-time, ALBERT performs better than BERT.
Why It Matters: These results are promising, showing that simply building more complex, larger, deeper models is not always the best approach to improving model performance.
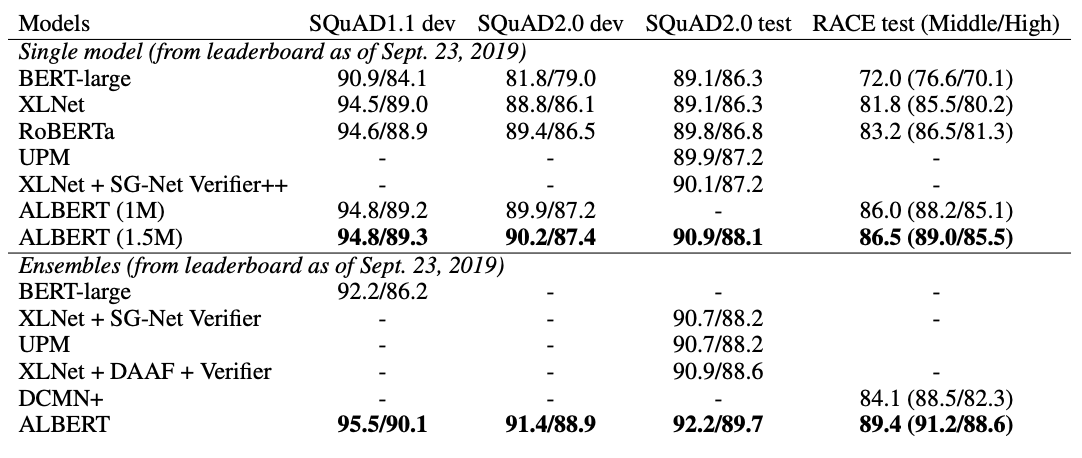 State-of-the-art results on the SQuAD and RACE benchmarks
State-of-the-art results on the SQuAD and RACE benchmarks
[Encoding Word Order in Complex Embeddings](https://arxiv.org/pdf/1912.12333.pdf
Benyou Wang, Donghao Zhao, Christina Lioma, Qiuchi Li, Peng Zhang, Jakob Grue Simonsen
Main Contribution: This paper describes a new language model that captures both the position of words and their order relationships. The paper redefines word embeddings (previously thought of as fixed and independent vectors) to be functions of the word’s position. The author’s Transformer Complex-Order model outperforms the Vanilla Transformer and complex-vanilla Transformer by 1.3 and 1.1 in absolute BLEU score respectively.
Why It Matters: Position embeddings capture the position of individual words, but not the ordered relationship (e.g., adjacency or precedence) between individual word positions. Their approach allows word representations in different positions to correlate with each other in a continuous function.
Reformer
Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya
Main Contribution: The authors propose a new transformer model with two major improvements to the architecture: a) using reversible layers to prevent the need of storing the activations of all layers for backpropagation, and b) using locality sensitive hashing to approximate the costly softmax(QK^T) computation in the full dot-product attention
Why It Matters: The Reformer performs on par with SOTA Transformer models while being much more memory-efficient and much faster on long sequences. For examples, the Vaswani et al. (2017) base model had a BLEU score of 27.3 compared to Reformer’s BLEU score of 27.6 on newstest2014 for WMT English-German.
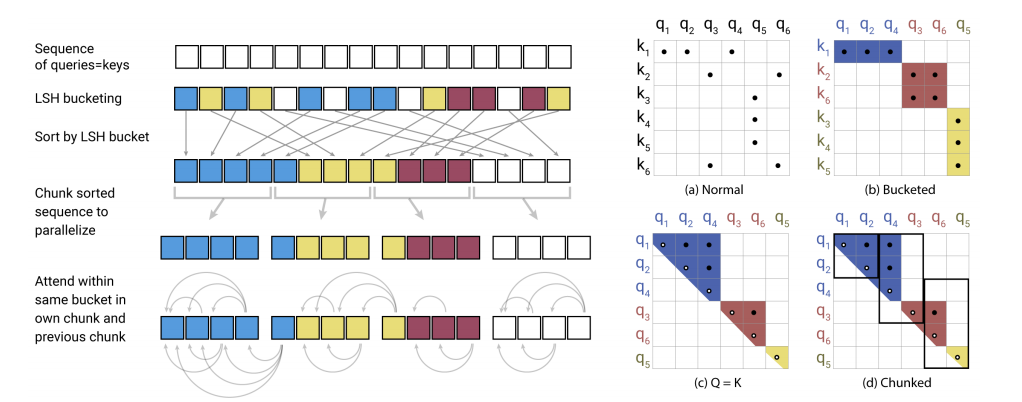 On the left, Locality-Sensitive Hashing Attention showing the hash-bucketing, sorting, and chunking steps and the resulting causal attentions. On the right, (a-d) Attention matrices for these varieties of attention.
On the left, Locality-Sensitive Hashing Attention showing the hash-bucketing, sorting, and chunking steps and the resulting causal attentions. On the right, (a-d) Attention matrices for these varieties of attention.
Thieves on Sesame Street! Model Extraction of BERT-based APIs
Kalpesh Krishna, Gaurav Singh Tomar, Ankur P. Parikh, Nicolas Papernot, Mohit Iyyer
Main Contribution: This paper highlights an exploit only made feasible by the shift towards transfer learning methods within the NLP community: for a query budget of a few hundred dollars, an attacker can extract a model that performs only slightly worse than the victim model on SST2, SQuAD, MNLI, and BoolQ. On the SST2 task, the victim model had a 93.1% accuracy compared to their extracted model’s 90.1%. They show that an adversary does not need any real training data to mount the attack successfully. The attacker does not even need to use grammatical or semantically meaningful queries. They used random sequences of words coupled with task-specific heuristics to form useful queries for model extraction on a diverse set of NLP tasks.
Why It Matters: Outputs of modern NLP APIs on nonsensical text provide strong signals about model internals, allowing adversaries to train their own models and avoid paying for the API.
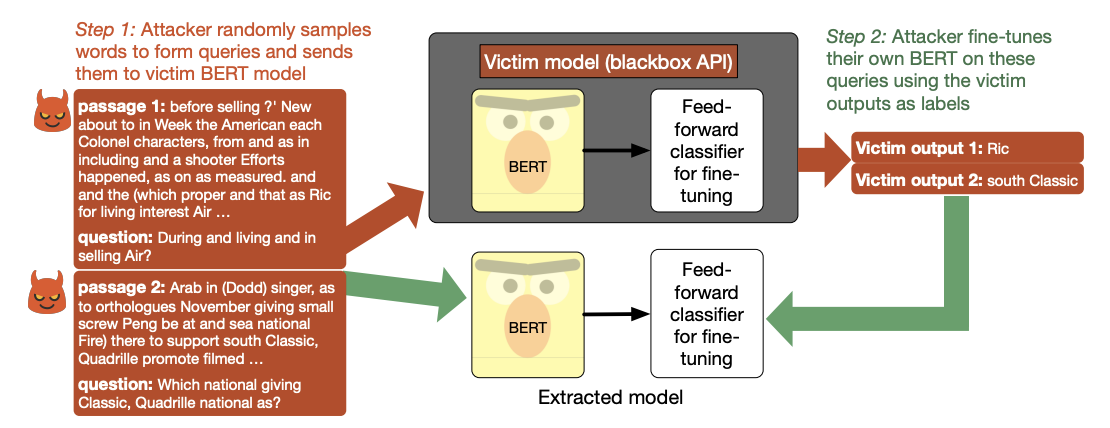 Overview of the proposed model’s extraction setup for question answering
Overview of the proposed model’s extraction setup for question answering
Questions? Concerns? Snarky comments about papers I missed? Any and all feedback welcome. Ping me in the comments below or on twitter @christinahkim