Building upon OpenAI’s recent work on scaling laws, my project explores how much pre-training on English helps when transferring across different languages.
Here, I will discuss scaling laws discovered while fine-tuning across different languages with pre-trained English language models. Specifically, I found that a) pre-trained English models help most when learning German, then Spanish, and finally Chinese and b) transfer from English to Chinese, German, and Spanish scales predictably in terms of parameters, data, and compute.
code | models | presentation
Introduction
Historically, the advancement of deep learning capabilities has centered around three levers: improved algorithms, faster and cheaper compute, and larger and higher quality datasets. Given machine learning’s promise to significantly impact society, deepening our general understanding of machine learning, and how certain levers improve models, is critical for making better predictions for which capabilities will develop next, and when. Recently, researchers have increasingly explored scaling relationships between these three levers.
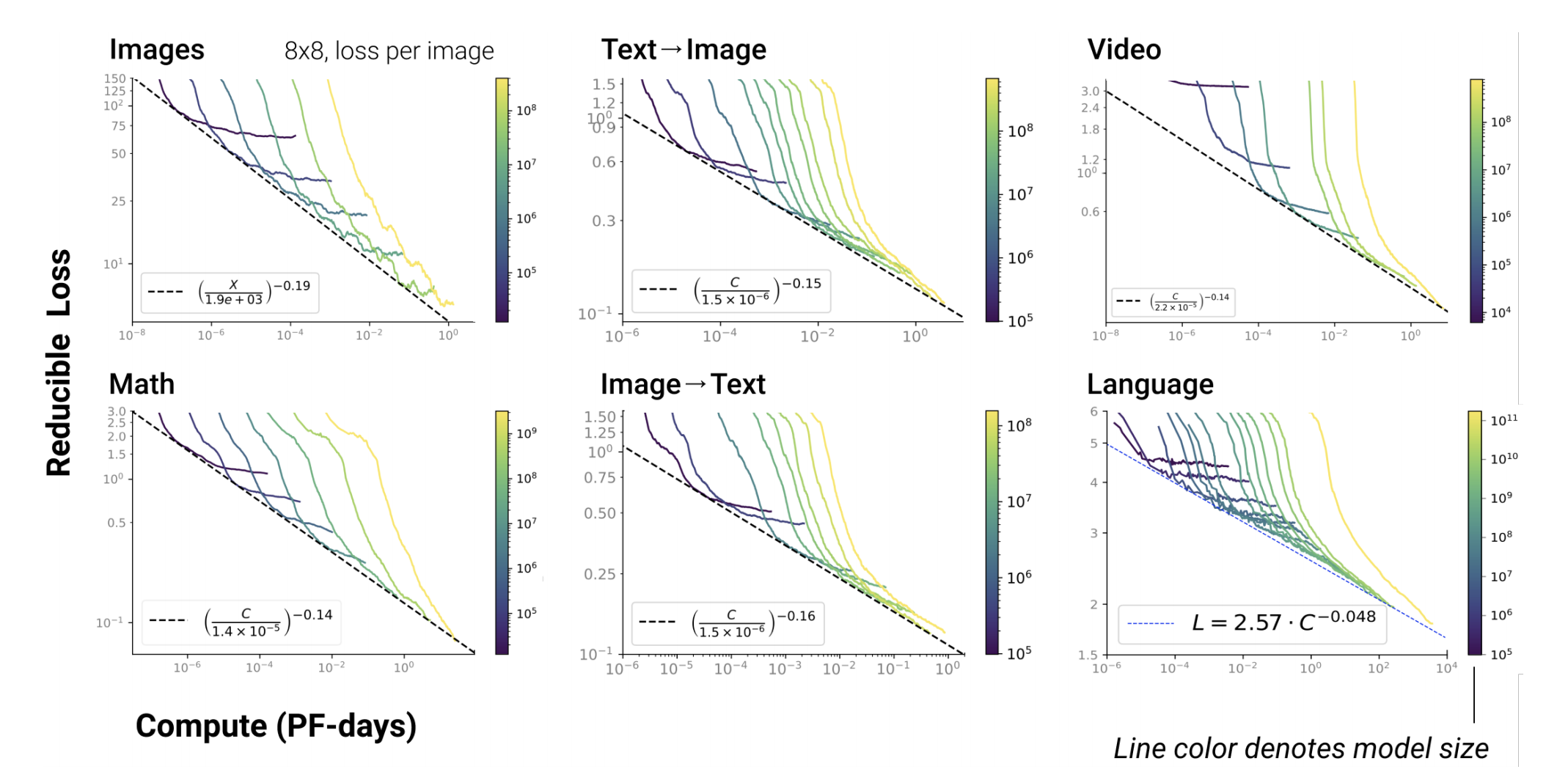
Fig 1. Figure from Henighan et al. 2020.
My project’s framework for experiments is inspired by the work on scaling laws published by OpenAI in the past year. Scaling laws (Kaplan et al. 2020) can predict machine learning performance as a function of model size, dataset size, and the amount of compute used for training. Henighan et al. (2020) also found that this relationship holds over several orders of magnitude across different modalities, as seen in the figure above. Earlier this year, scaling relationships were found for transfer learning from pre-trained english text models to Python (Hernandez et al 2021). These results show that compute, dataset size, and model size are different limiting factors that scale with each other in surprisingly predictable trends when we setup our experiments to measure those things.

In my project, I continue the study of transfer between distributions and look at scaling between three other languages and English. Scaling laws for transfer are important because the scaling relationships explain how to work in limited data regimes. In an ideal world, one would have an infinite amount of data for a model to learn from. However, getting a large quantity of high quality data is a nontrivial, if not impossible, task and as a result, most problems exist in the low data regime. Before the Scholars program, I was a machine learning engineer and saw firsthand how costly it was in terms of both time and money to get good quality human labels for our tasks. Exploring the relationships between different languages can provide more insight on how to tackle low-resource languages and how to best leverage pre-trained language models. Given the real world limitations of data, the tradeoffs between budgeting for compute on larger models and budgeting for more fine-tuning data is an important practical relationship to understand.
Experiment Methodology
Building upon work from Scaling Laws for Transfer (Hernandez et. al. 2021), my experiments focused on exploring the relationships between fine-tuning on non-English languages. My experiments try to answer the question: How much does pre-training on English help when transferring across different languages as we vary the dataset size and model size?
Pre-training
I first trained English language models in a similar setup to Scaling Laws for Neural Language Models. I pre-trained decoder-only transformers of size 124M, 70M, 51M, 39M, 16M, 3.3M, non-embedding parameters with the same hyperparameters on OpenWebtext2(65.86GB), an open-source version of WebText created by Eleuther AI. All models used Adam, a batch size of 512, context length of 1024 tokens, and a learning rate schedule with a 500 step linear warm-up with a cosine decay to 10% of the maximum learning rate. The text was encoded with a GPT2 tokenizer, a byte-level Byte-Pair Encoding tokenizer with a 50K vocab size. All models were trained for a total of 26 billion tokens with no repeats. The code to reproduce these pre-trained models is available on GitHub, including model weights. As seen in the figure below comparing loss and model size, the models exhibit scaling laws as model size increases. However, the relationship isn’t exactly linear, suggesting that maybe the models are under-trained or the hyperparameters are not tuned thoroughly.
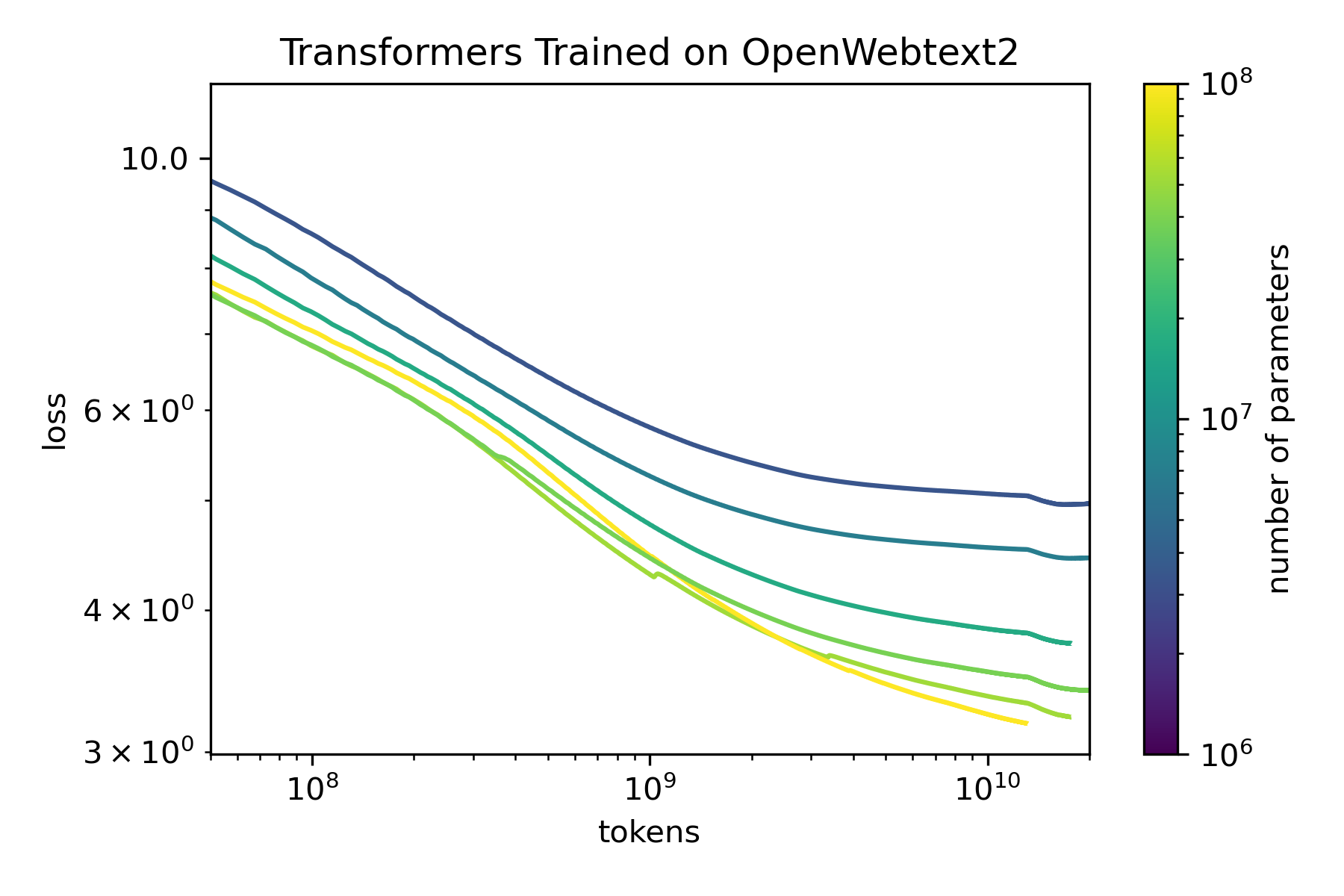
Fig 2. Training curves for transformers on OpenWebtext2. The larger models overlap with each other early in training which suggest the hyperparameters are not tuned thoroughly.
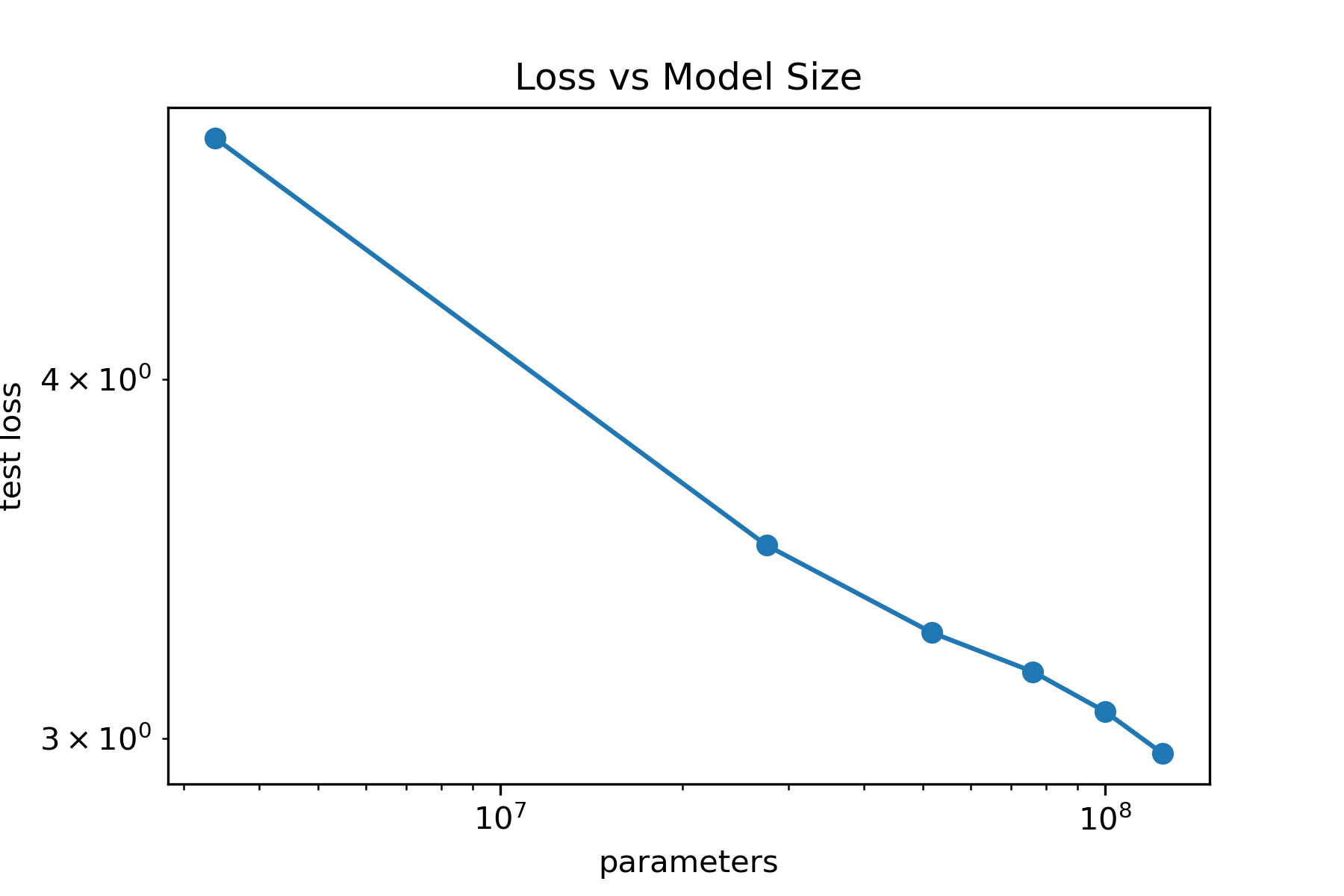
Fig 3. Language modeling performance improves as parameters increases, but the relationship is not linear.
Fine-Tuning
For the fine-tuning experiments, dataset size spanned six orders of magnitude, and model size spanned two orders of magnitude trained on three different languages: Spanish, Chinese, and German. Models trained or fine-tuned on Chinese datasets leveraged a 1.2 billion character dataset, Community QA. Community QA (webtext2019zh) is similar to the WebText corpus. Models trained or fine-tuned on Spanish texts and German texts are from Oscar, a multilingual corpus obtained by language classification and filtering of the Common Crawl corpus.
The models fine-tuned on non-English languages with the pre-trained English model weights, and the models trained on non-English languages from-scratch were all trained up to the optimal loss if the model started over-fitting or up to 15M tokens, whichever came first. Models were trained with a learning rate schedule of a 300 step warm-up with a cosine decay to 10% of the maximum learning rate. The code to replicate these experiments will also be available on GitHub.
Results
Effective Data Transfer
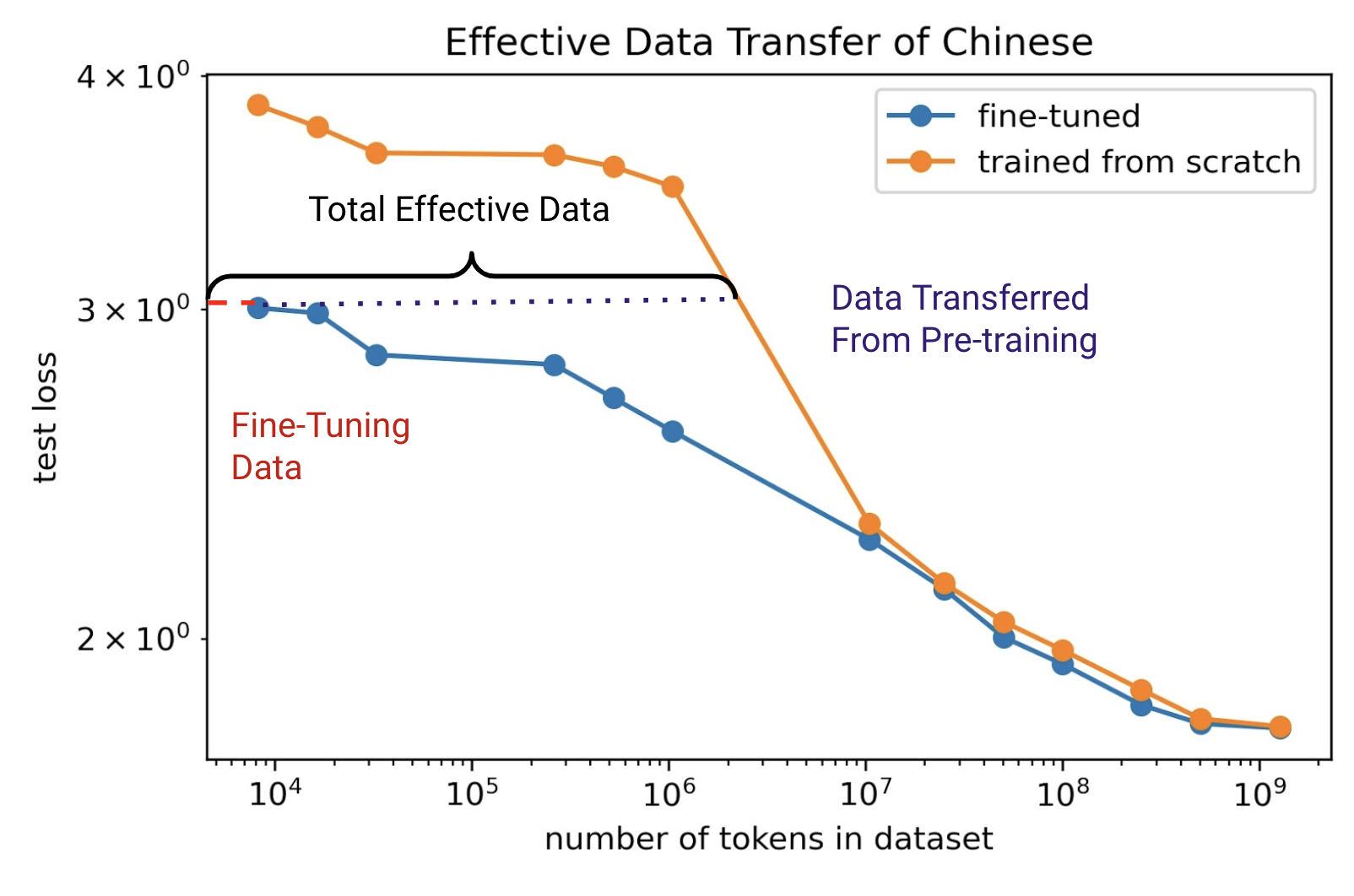
Fig 4. The performance of a 16M parameter transformer model on Chinese, both trained from scratch on Chinese and pre-trained on English then fine-tuned on Chinese.
In my experiments, I wanted to find the effective data transferred for models trained on English text to Chinese, Spanish, and German text. The effective data transferred is defined in Scaling Laws for Transfer as the amount of additional fine-tuning data that a model of the same size, trained on only that fine-tuning dataset, would have needed to achieve the same loss as a pre-trained model. In the figure above, each point is a 16M transformer trained to convergence on dataset of X tokens. The total amount of data required for the model trained from scratch can be represented as $D_e = D_f + D_t$ where $D_e$ is the total amount of effective data, $D_f$ is the amount of data needed for the fine-tuned model, and $D_t$ is the amount of additional data needed for the trained from scratch model. $D_t$ is the amount of data transferred from pre-training on English.
Fig 5. Comparing performance of a 16M parameter transformers trained from scratch, and fine-tuned on Chinese, Spanish, and German. For the dataset size of 8000 tokens, $D_t$, the amount of data transferred, is largest for German. The dashed line on the graphs represent $D_t$. As the number of tokens in the dataset size increase, $D_t$ becomes smaller across all languages.
As seen in the figures above, English to Chinese had a smaller amount of data transferred compared to English to Spanish for the same model size and English to German had the greatest amount of data transferred. Pre-trained English text models help most when learning German, followed by Spanish, and finally, Chinese. I believe these results reflect the degree of linguistic similarities between English and the non-English languages. English and German are both derived from Proto-Germanic and are linguistically most similar. Although the Spanish alphabet shares almost all the same symbols with the English alphabet, it is a Romance language, and Chinese does not share the same alphabet as English. Each language has a distinctive shape and distance between fine-tuning and training from scratch. For instance, the effective data transfer is not too much greater for Spanish, vs Chinese, at the smallest dataset size, 8000 tokens. However, as we increase the dataset size, pre-training continues to help for another order of magnitude until the 100M token dataset size than the Chinese which converges at 10M token dataset size.
Comparing the Fraction of Effective Data from Fine-Tuning, $D_f /D_e $
$D_f /D_e $ measures the fraction of effective data from fine-tuning. A smaller fraction means pre-training helps more. I found that as model size increases, $D_f /D_e$ decreases across all languages and pre-training becomes more effective. However, as dataset size increases, $D_f /D_e$ increases across model sizes and pre-training becomes less effective. In the figure above, German has steeper curves, seeing the effective data from fine-tuning decrease the most, which shows English helps the most while Chinese has the flattest curves, showing pre-training helps the least for Chinese.
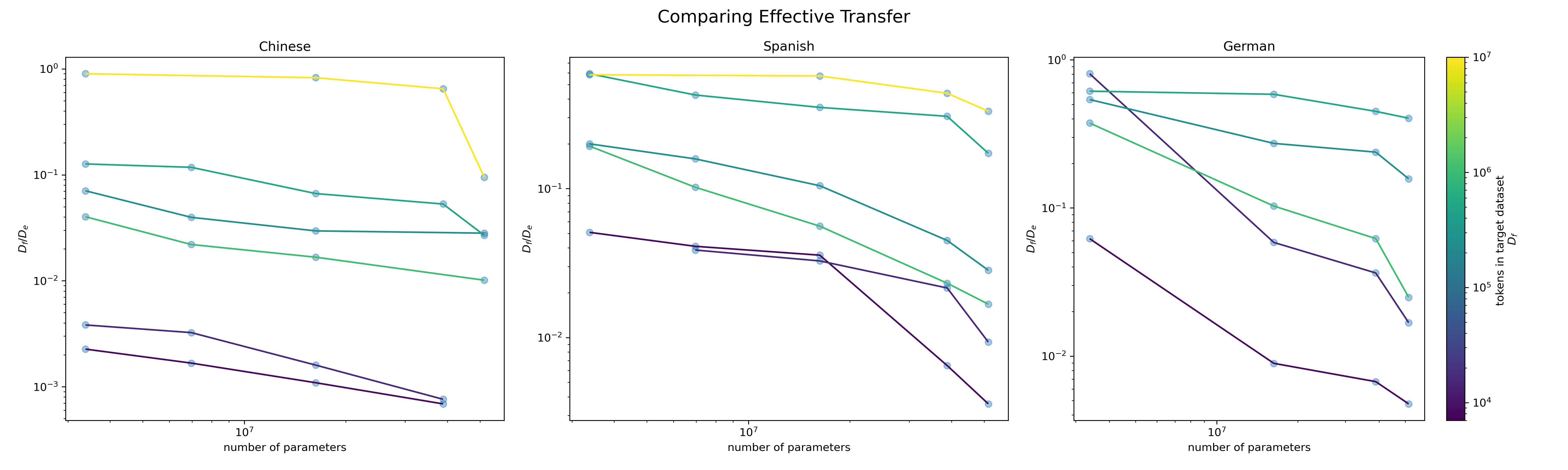
Fig 6. Comparing the fraction of effective data from fine-tuning of a 16M parameter transformer model on Chinese, Spanish, and German.
I find many of the same trends and relationships found in the Scaling Law for Transfer between text and code, between English and different languages.
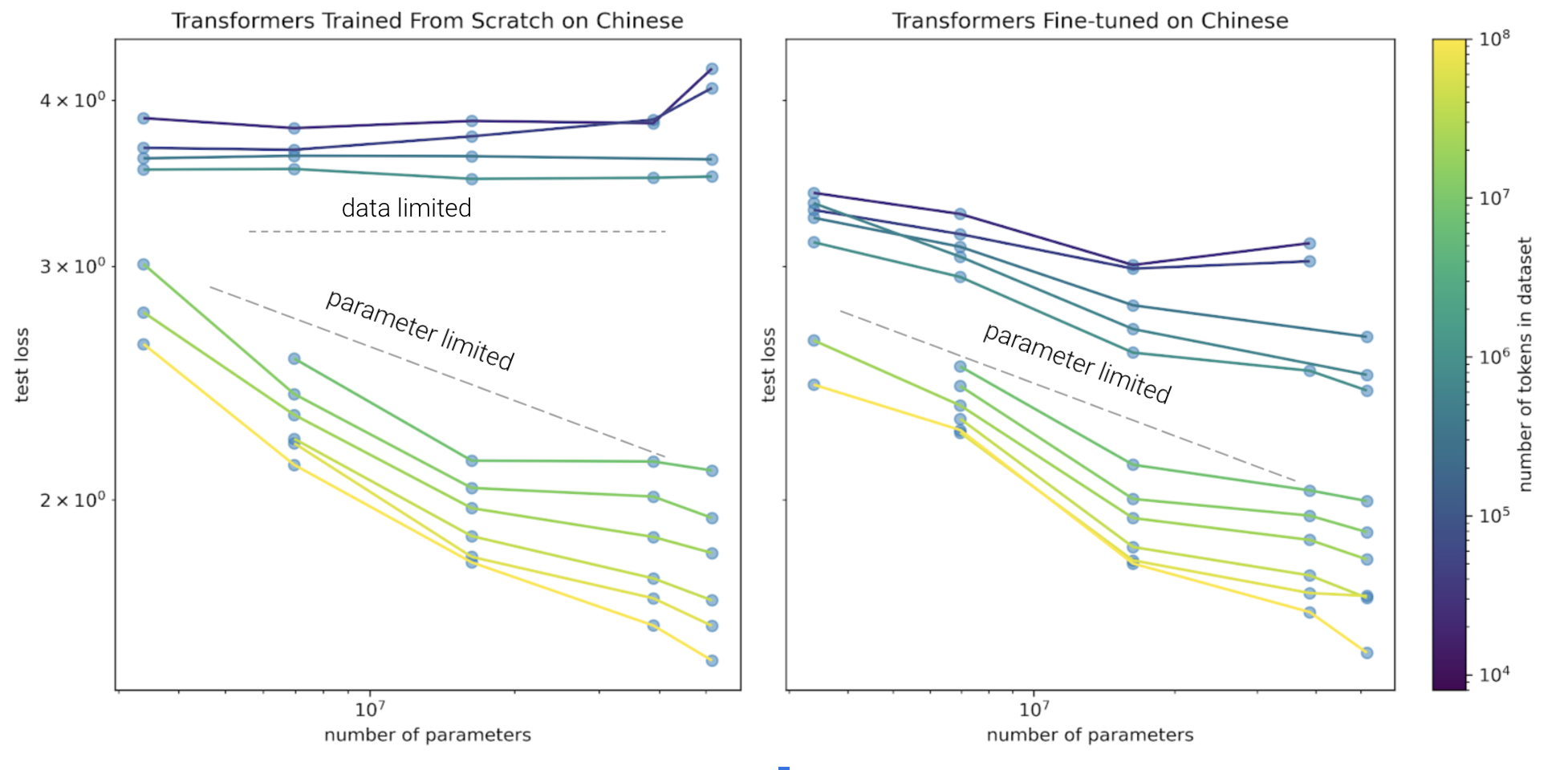
In the low data regime, pre-training is helpful across model sizes, but especially in large model sizes. When using pre-trained models, model performance is parameter limited. Model performance is considering parameter limited when the loss continues to decrease as we increase the model size. Model performance is data limited when increasing the number of parameters does not impact the loss. This is evident in the figure above, which shows that as model size increased with a fixed dataset size of Chinese text to fine-tune on, models trained from scratch on Chinese did not improve as much while models that were pre-trained on English improved more to achieve better performance. The flat lines indicate the performance is data limited, while the sloped lines indicates the performance is more limited by the number of parameters.
Lastly, pre-trained models are more compute efficient than training from-scratch across dataset sizes. This is without accounting for the compute costs for the pre-trained model.
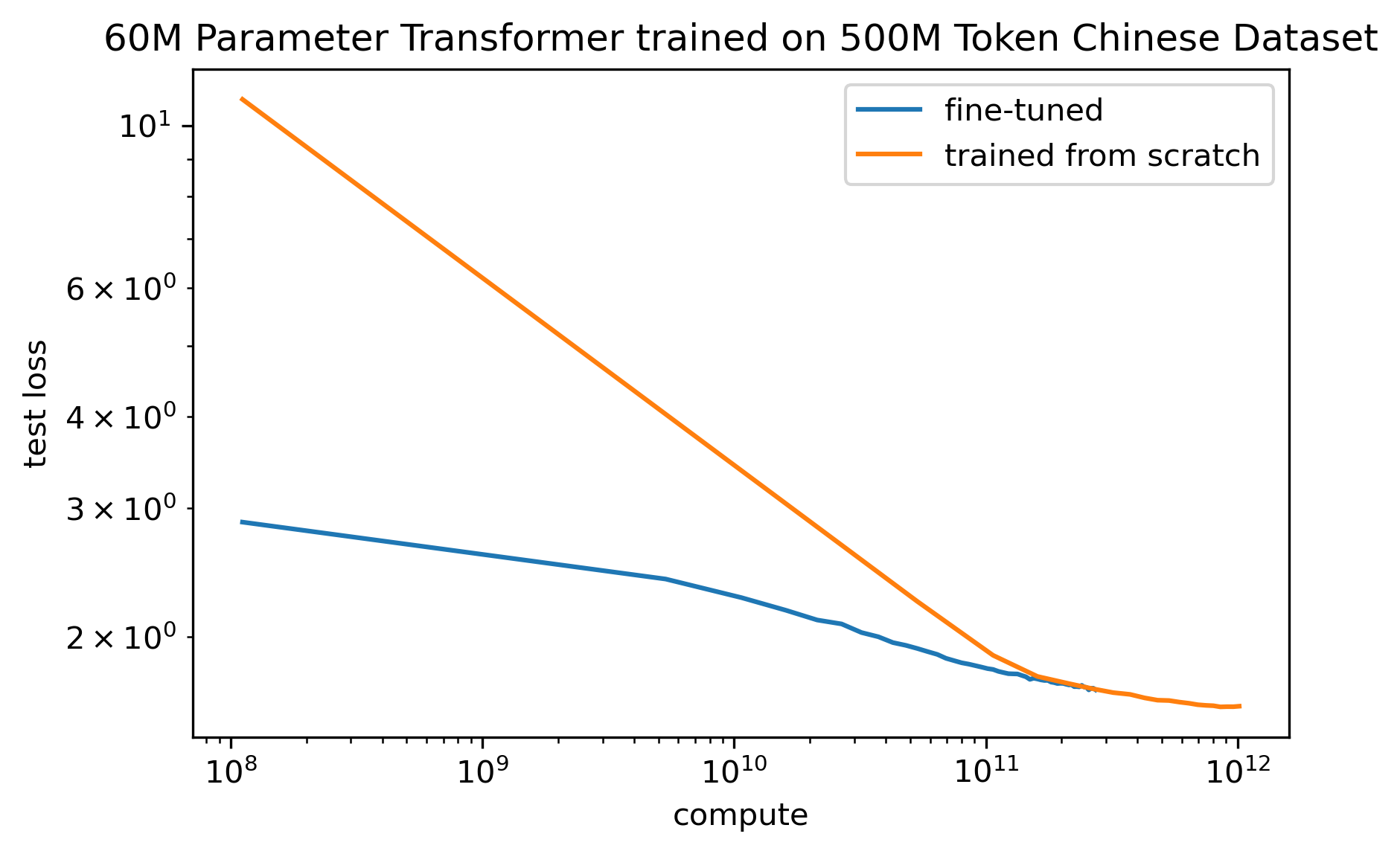
Fig 7. Comparing amount of compute needed for a 60M transformer trained from scratch and fine-tuned on 500M tokens of Chinese
Limitations
There are important limitations of my work. First, I used the same BBPE GPT-2 tokenizer for all languages. This is extremely inefficient for the non-English languages since the tokenization requires more tokens to represent the language. For example, Chinese is upwards of 50K characters, while the BBPE tokenizer used a 50k vocab size. Second, my largest models could have been pre-trained for longer. For scaling law experiments, it’s important to make sure models are in the correct regime, either convergence frontier, or compute frontier. Additionally, I was only able to do a limited hyperparameter sweep and learning rate schedules due to compute and time. I suspect the results found are very learning rate schedule dependent. Finally, my fine-tuning datasets were from different sources. This is important to note since my results maybe more specific to the distribution found in the dataset than the underlying language.
Future Work
Some potential future directions include:
- Compare the effective data transfer using pre-trained models in Chinese, German, Spanish, then fine-tuned to English
- Fine-tune with low resource languages or other tasks/distributions and find the effective data transfer
- Predict ideal ratio for pre-trained v.s. fine-tune for any given problem, given some budget
- Study the “forgetting” problem in transfer learning in terms of effective data transfer
Acknowledgements
Thanks to my mentor Jerry Tworek, the Scholars cohort, Danielle Ensign and Kudzo Ahegbebu for sharing compute, everyone that gave me feedback (especially Danny Hernandez and Mohammad Bavarian), Jeromy Johnson for helping me find the Community QA dataset, Scholar program coordinators, Muraya Maigua and Christina Hendrickson, and OpenAI and Azure for making this all possible.
Citation
If you find this work useful, please cite it as:
@article{kim2021scalinglanguagetransfer,
title = "Scaling Laws for Language Transfer Learning",
author = "Kim, Christina",
journal = "christina.kim",
month = 4,
year = "2021",
url = "https://christina.kim/2021/04/11/scaling-laws-for-language-transfer-learning/"
}
References
Jörg Bornschein et al. Sep 26, 2020. Small Data, Big Decisions: Model Selection in the Small-Data Regime
Frédéric Branchaud-Charron et al. May 20, 2019. Spectral Metric for Dataset Complexity Assessment
Tom Henighan et al. Oct 28, 2020. Scaling Laws for Autoregressive Generative Modeling
Henning Fernau. Jan 24, 2019. Algorithms for Learning Regular Expressions from Positive Data Algorithms
Pierre Guillou. Jul 3, 2020. Byte-level BPE, an Universal Tokenizer but…
Danny Hernandez et al. Feb 2, 2021. Scaling Laws for Transfer
Joel Hestness et al. Dec 1, 2017. Deep Learning Scaling is Predictable, Empiricially.
Jared Kaplan et al. Jan 23, 2020. Scaling Laws for Neural Language Models
Ameet A. Rahane et al. Apr 16, 2020. Measures of Complexity for Large Scale Image Datasets
Jonathan S. Rosenfeld et al. Sep 25, 2019. A Constructive Prediction of the Generalization Error Across Scales
Céline Van den Rul. Nov 9, 2019. [NLP] Basics: Measuring The Linguistic Complexity of Text